

What if I told you that the source code, or genomes, for many living organisms is available for free online? Would it surprise you? As of today, all genomes created by public funds are accessible to anyone in the world. Anyone with internet access, and a little bit of curiosity, can access tomes of genetic information at a click of a finger. However, while these genomes remain open to the public for anyone to download, the information that makes these resources valuable and interesting remain behind paywalls. But before we dive into the issues of accessibility, it's worth reflecting on just how quickly this type of genomic data increased. Just take a look at the National Center for Biotechnology Information (NCBI), which houses a huge amount of genomic data from diverse species.

To date, NCBI has sequence data for over almost 50,000 genomes belonging to diverse organisms, pretty much from alligators to zebras. Considering that the first Eukaryotic genome, budding yeast was published in 1996, this amounts to about five new genome being sequenced, and published every single day. The fathers of science fiction – Asminov, Huxley, Welles – couldn't have predicted such a radical shift in speed and accessibility in scientific information. However, it's important to realize that while these resources are accessible to anyone, the tools to understand these complex by products of billions of years of evolution remain guarded by the old establishments of scientific journals.
For instance, let's say you're interested in the baboon genome, which you can find after a Google search and a few clicks around. You might be interested in what those authors found in their initial study, as well as ask the question “Why even sequence the baboon genome?†(a good question), or “What did the authors find?†(another good question!). However, once you click on the link to the publication the authors, you're greeted with an unpleasant reality. Those answers cost money.
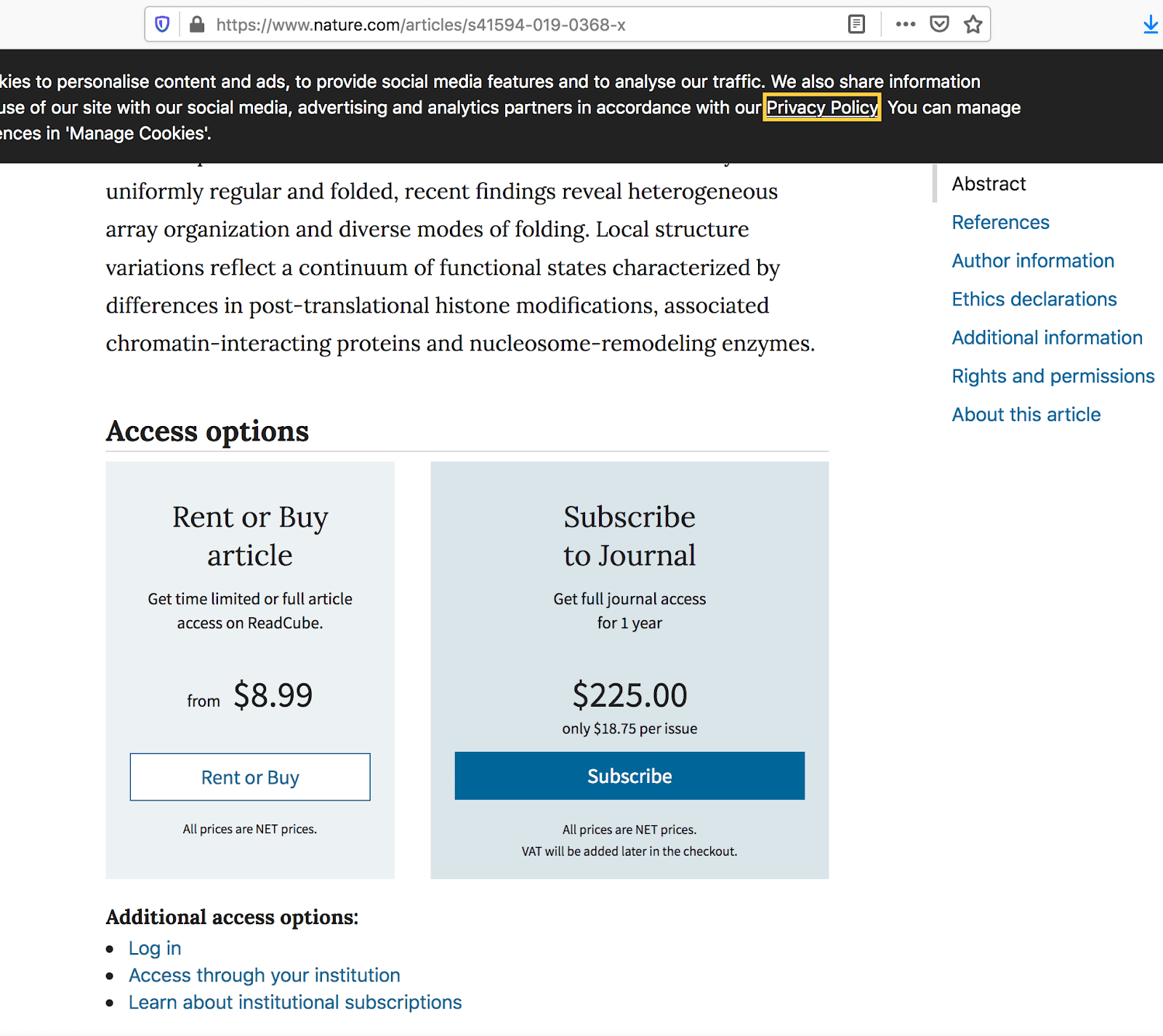
If you're unaware, most scientific journals require one of the following: 1) a subscription costing $200 a year, 2) institutional access, or 3) purchasing an individual article for the price of $80. Any of these three avenues is greatly restrictive to the average scientifically curious person, making that baboon article more than likely not worth the price. So, what is someone to do with the wealth of genomic data available to the public, when any insights gleaned from it aren't?
It's worth mentioning this isn't a new issue. In the last few decades the idea of “open access scienceâ€, or free access to scientific journals, has been discussed in great detail. With publications like the New York Times posting stories about scientists sick of the closed nature of science. It's gotten so dire that some scientists took it upon themselves to pirate all known scientific journals and make them accessible to anyone in the world in the form of a piratebay-like site called sci-hub. The scientific journal establishment has taken the creation of this website seriously, and has charged the creator of sci-hub, Alexandra Elbakyan with a record fine of some four million dollars in damages.
And yet, the process of publishing and restricting science continues. The result is on par with an illiterate person gaining access to a library. While wondrous in its own right, what good is it for someone who cannot read? Resources created with public tax dollars that are accessible to all, and yet the understanding and scientific stories remain hidden in what can only be envisioned as the scientific equivalent of a dragon’s horde. It raises an interesting question: what value do these genomes really have if the knowledge accompanying them isn't accessible? Is there any value in them at all?
For further reading of the current war of scientific journals and open access, check out this excellent Verge piece.
About the Author
 Pablo Mendieta is a graduate student pursuing a PhD in bioinformatics and genomics at the University of Georgia. His specific interest lie at the intersection of agriculture, and genetic technologies. From Boulder Colorado, he enjoys the outdoors, science fiction, programming, and hip hop. You can email him at john.mendieta@uga.edu or connect with him on Twitter. More from Pablo Mendieta.
Pablo Mendieta is a graduate student pursuing a PhD in bioinformatics and genomics at the University of Georgia. His specific interest lie at the intersection of agriculture, and genetic technologies. From Boulder Colorado, he enjoys the outdoors, science fiction, programming, and hip hop. You can email him at john.mendieta@uga.edu or connect with him on Twitter. More from Pablo Mendieta.
Featured image credit: Anna Marchenkova via Wikimedia Commons licensed under Creative Commons Attribution 4.0 International.






{kind=link}