

Anyone who has read my previous post on “Why Computers Can't do Everything†knows the Information Technology industry has an uncanny ability to generate a variety of buzzwords to try to convince the public that their computing capability has no limits. In fact, these “buzzwords†have generated so much public interest that Gartner, Inc., a world-renowned research firm, created the Gartner Hype Cycle to measure technologies lifecycles in terms of its real world applications and social adoption. One recent trend that is becoming increasingly popular with IT professionals and aspiring computer scientists alike is that of “Big Dataâ€.
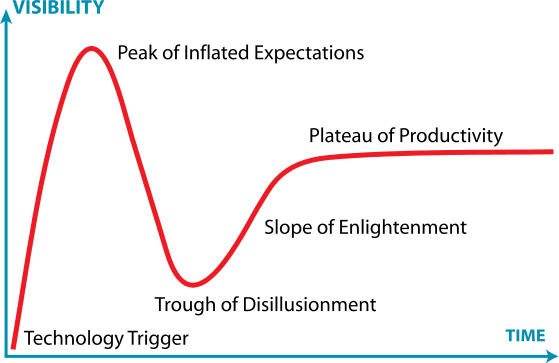
Aside from being an overused term in my statistics and computer science classes, big data is also a very ambiguous term. It can be used to simply mean incredibly large datasets, or it can be used to refer to the analytical methods that extract value from these datasets. Nevertheless, big data is often used hand-in-hand with another technology buzzword: machine learning.
Without getting too technical, machine learning simply refers to computational techniques that allow computers to “learn†what to do without being explicitly told by programmers. It just so happens that machine learning also appears at the top of the “Peak of Inflated Expectations†in the 2016 Gartner Hype Cycle (see the image above).
*Note: Throughout this piece, machine learning will refer to analytical methods that extract values from large datasets, and big data will simply refer to these large datasets.
While there have certainly been some great uses of machine learning, such as Google Flu Trends outperforming the CDC methods of flu outbreak tracking (although it didn't last long), it could be argued that big data is raising more problems than solutions. Due to its newfound popularity, it is important that businesses and consumers remain healthy skeptics in order to realize what big data can and can't do for society.

One of the biggest impediments to big data and machine learning reaching the “Slope of Enlightenment†is that a lot of businesses simply don't know what to do with the data they are collecting. A recent survey of 308 IT decision makers in the UK, France, and Germany found that 72% of organizations have collected data that was never used later on. Not only that, but the survey also found that only 36% of respondents believed that their company was even collecting the right data to make business decisions. This raises the point of just because we CAN collect huge amounts of data, doesn't necessarily mean that we SHOULD.
Along with the huge collection of data comes the ethical dilemmas of data privacy. In order for machine learning to produce any meaningful and accurate insights, they inherently rely on collection of personal information. While most of the data being collected on humans is fairly non-threatening, there is still the potential for sensitive information to be released. This problem has proven to be so complex that the U.S. government is still debating how to regulate internet privacy rules.
Aside from the knowledge gap of what data is truly useful and the ethical concerns of data privacy, perhaps the biggest problem with big data is that it often falls flat on its face with more complex problems. For example, it's easy for a computer to determine if an image is of a cat or a dog (in fact, there's a competition every year to see which computer algorithm can do it best), but it's harder for it to determine if its a cat, a dog, a horse, or a car. In the end, we don't care about the simple problems. Therefore, there should still be skepticism surrounding the utility of big data.
A real world example of a recent machine learning failure is when almost every major vote forecaster predicted that Hillary Clinton would win the 2016 Presidential Election with ease. Big data technologies often rely heavily on general pattern recognition, and can miss important contexts and small nuances. Even with all this data, machine learning just wasn't smart enough.
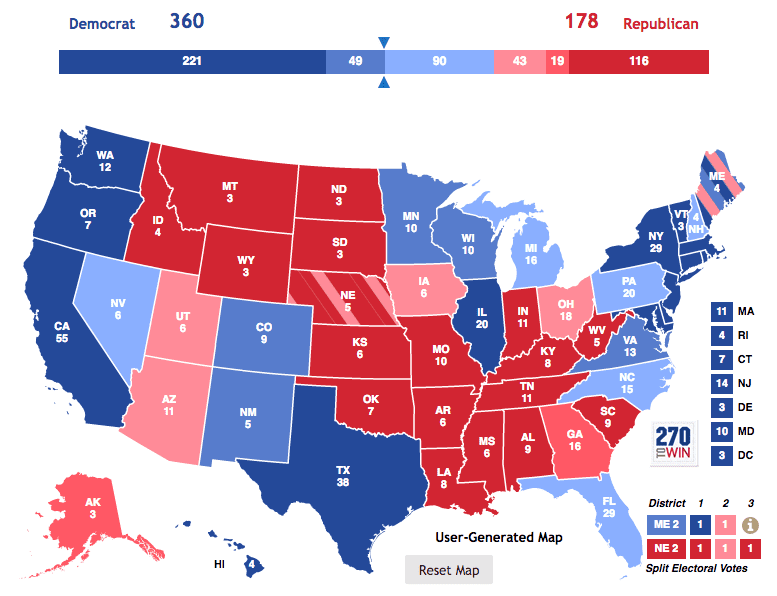
Despite all the hype, it is clear that there are still some unsolved problems surrounding the big data industry. While I am all for the progression of research in machine learning, having even done some myself, these are issues that cannot be ignored. Computer scientists must begin to question what data to collect and for what purpose. They must begin to question if their predictive analytics really provide any useful insights to incite change. Most importantly, they must continue to be healthy skeptics.
 Jonathan Waring is an Athens native and an undergraduate student studying Computer Science at the University of Georgia. When he's not watching Netflix in his room, he can be found watching Netflix in his friends' rooms. He aspires to pursue an advanced degree in Medical Informatics and to one day work on disease tracking software at the CDC. As a reminder he is just one person: not statistically significant nor representative. You can email him at jwaring8@uga.edu or follow him on Twitter @waringclothes. More from Jonathan Waring.
Jonathan Waring is an Athens native and an undergraduate student studying Computer Science at the University of Georgia. When he's not watching Netflix in his room, he can be found watching Netflix in his friends' rooms. He aspires to pursue an advanced degree in Medical Informatics and to one day work on disease tracking software at the CDC. As a reminder he is just one person: not statistically significant nor representative. You can email him at jwaring8@uga.edu or follow him on Twitter @waringclothes. More from Jonathan Waring.






{kind=link}