Ahh sarcasm. Whether you love it or hate it, sarcastic comments have become quite common on the Internet. This is especially true on sites where people are more likely to express their opinions, such as blog posts, product reviews, social media, message boards, etc. By its very nature, sarcasm can be pretty ambiguous which makes it hard even for humans to detect if a comment is sarcastic or not. Sarcasm is usually detected in face-to-face communication through vocal tone and facial cues that communicate the speaker's intent. However, detecting it in plain writing can be much more difficult for people.
If you think that humans have a hard time detecting sarcasm, imagine how difficult it must be for computers. Computers are typically programmed to process text exactly as they see it, which can be problematic when you consider the fact that sarcasm is just saying the opposite of what you mean. But why do we care if computers can detect sarcasm or not?
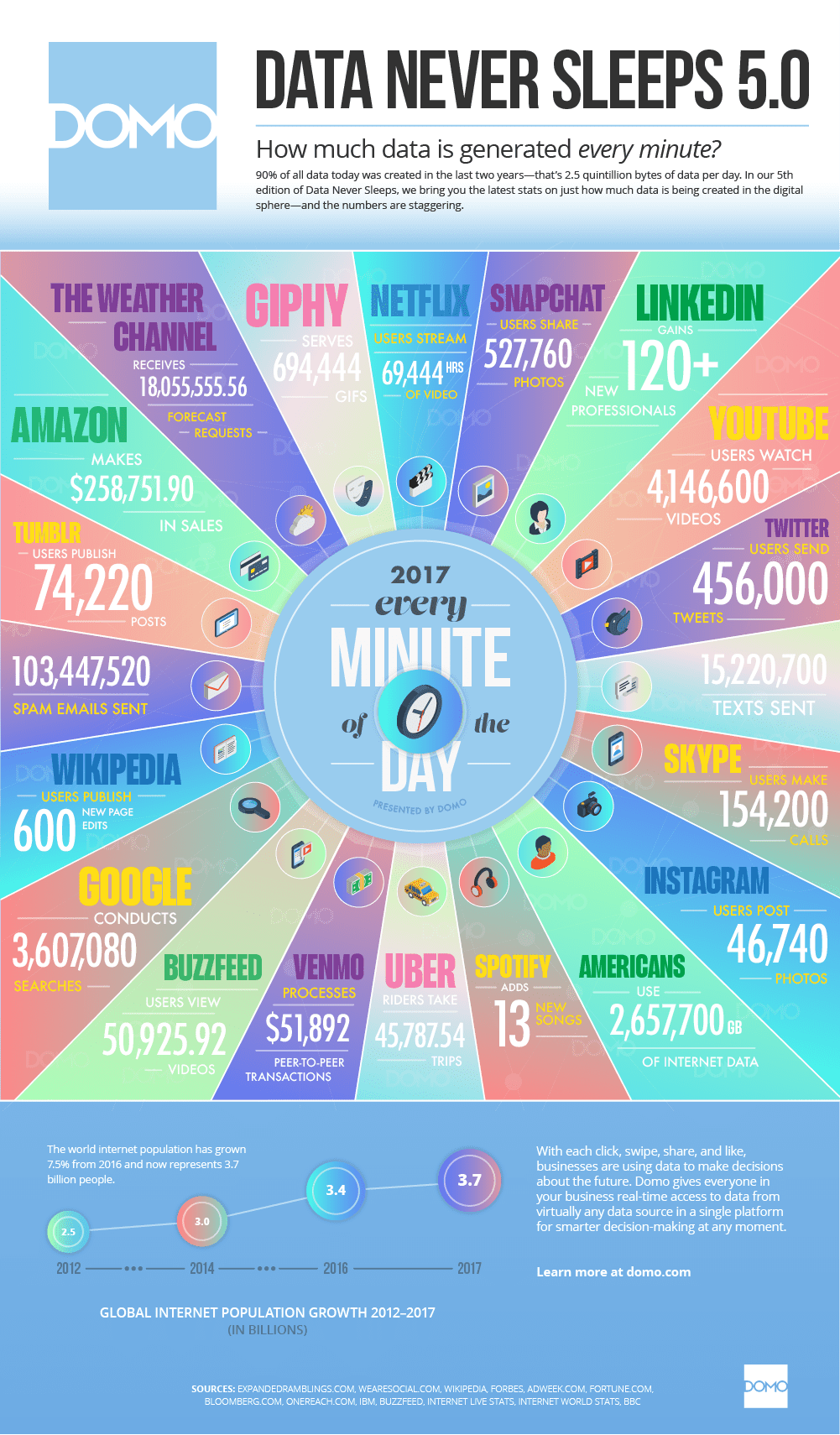
There's actually been quite a few people who have expressed interest in the area, including the Secret Service, which posted a request for an automated software that detected whether threats on Twitter were serious or not. But why can't humans just do it themselves if we're better at detecting sarcasm in the first place? Because there are massive amounts of text data being generated every minute, including 456,000 tweets, 74,220 tumblr posts, 600 new Wikipedia edits, 15,220,700 texts sent, etc. As discussed in my previous blog post Mo' Data Mo' Problems, there's just not enough manpower to process all of this data.
So why is detecting sarcasm such a challenge for computers? To answer that question, we need to take a closer look at the subfield of artificial intelligence (AI) known as Natural Language Processing (NLP).
As the name implies, NLP is a field of study that is concerned with how computers analyze, understand, and/or derive meaning from human language. NLP techniques are much more than just your common word processor which just treats text as a sequence of letters and numbers. NLP is more concerned with the structure of human language in which words make phrases, and phrases make sentences, and sentences convey ideas and meaning.
There have been multiple uses of NLP algorithms so far, including summarizing text, creating chatbots, classifying documents, identifying the emotional sentiment behind text, and automated question answering. Despite this fact though, NLP still fails in certain areas. Even though language can be one of the easiest things for us to learn and understand as we grow and develop as humans, language can still be too ambiguous for computers to master, especially with sarcasm, which inherently conveys contradictions given that you mean the opposite of what you say.

Despite sarcasm detection being such a hard task, a recent study showed that a new computer algorithm outperformed humans in detecting sarcasm on Twitter. The researchers took image and caption data, and had people from all over the world determine if the caption was sarcastic or not. Then by using a combination of image processing and NLP techniques, the researchers programmed the computer to learn from what the humans had taught them about the data.
Let's take a closer look at how this happened. When training a classification algorithm, there are two separate phase in programming: training and testing. In the training phase, the computers are given a bunch of sarcastic and non-sarcastic comments, and the programmers let the computers know whether or not the comment is sarcastic (as determined by the human labeling mentioned above). Using these training examples, the computer then tries to learn what makes comments sarcastic or not.
During the testing phase, the computer is again given a combination of sarcastic and non-sarcastic comments, but this time the computer doesn't know the comments' label. The computer then tries to classify the comments as sarcastic or not based on what it has learned. The aforementioned study showed that the computer algorithm had an 82.4% accuracy in detecting sarcasm, whereas humans only succeeded 76.1% of the time.
The reason this algorithm was so successful is that the researchers were trying to learn more about the context of the sarcastic caption by including the images in the learning process as well. It turns out that context makes all the difference in the world when teaching computers to be more like humans. Which is just what we needed, right?
Featured Image Credit: Binary Code by Christiaan Colen via Flikr
 Jonathan Waring is an Athens native and an undergraduate student studying Computer Science at the University of Georgia. When he's not watching Netflix in his room, he can be found watching Netflix in his friends' rooms. He aspires to pursue an advanced degree in Medical Informatics and to one day work on disease tracking software at the CDC. As a reminder he is just one person: not statistically significant nor representative. You can email him at jwaring8@uga.edu or follow him on Twitter @waringclothes. More from Jonathan Waring.
Jonathan Waring is an Athens native and an undergraduate student studying Computer Science at the University of Georgia. When he's not watching Netflix in his room, he can be found watching Netflix in his friends' rooms. He aspires to pursue an advanced degree in Medical Informatics and to one day work on disease tracking software at the CDC. As a reminder he is just one person: not statistically significant nor representative. You can email him at jwaring8@uga.edu or follow him on Twitter @waringclothes. More from Jonathan Waring.